Этот пост – продолжение изысканий на тему статистического анализа текстов. В прошлый раз, я строил функцию распределения текста по длине предложений. В этот раз я исследую слова из которых состоит текст. Строится функция распределения по длине слов. Также находится среднее число букв в слове и дисперсия распределения.
Вот например функции распределения по длинам слов для Чеховских рассказов. Было взято два куска текста (по нескольку рассказов в каждом) и вот что получилось:
Длина текста 1: 44041 символа
Длина текста 2: 42092 символа
Результаты (текст 1):
Среднее число букв в слове: 4.9152414106251
Дисперсия: 3.0963669515686
Результаты (текст 2):
Среднее число букв в слове: 4.957320971867
Дисперсия: 3.0301554718235
И график:
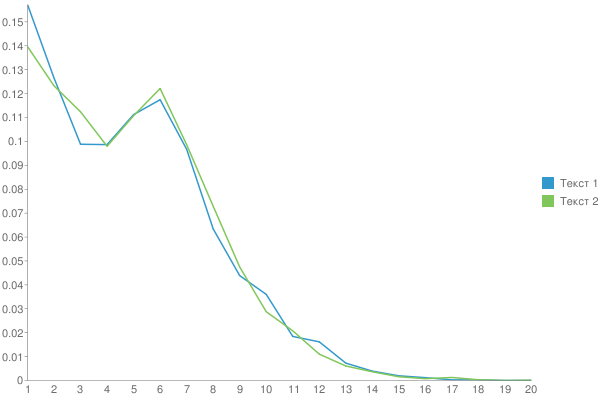
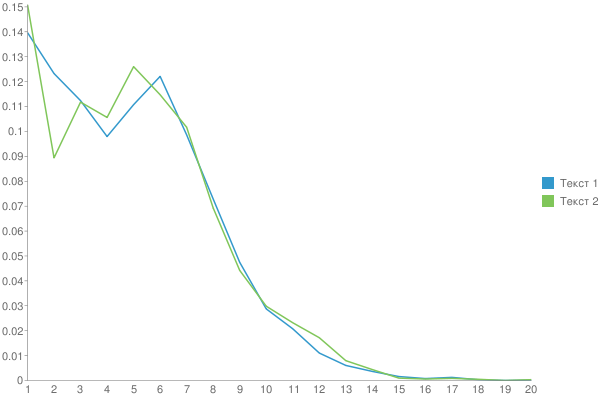
Сравнение текстов Чехова и Бунина (Жизнь Арсеньева):
Длина текста 1 (Чехов):42092
Длина текста 2 (Бунин):51693
Результаты (текст 1):
Среднее число букв в слове: 4.957320971867
Дисперсия: 3.0301554718235
Результаты (текст 2):
Среднее число букв в слове: 5.0579781353642
Дисперсия: 3.0793189863174
Графики:
Потестировать анализатор текста можно:
тут , если нужно сравнивать два разных текста, и тут , если нужно проанализировать один текст.
Графики строятся с помощью AJAX API Google.